
板块导航
热门下载
- · v2-fa7b535bc7f07f9b2be4d06179f02cc9_1440w.jpg
- · v2-8646f77c807187710b056e1c2f85daea_1440w.jpg
- · v2-3c8df5e1b5d19b93601fb58813e133e4_1440w.jpg
- · v2-1dee8d649eb2bb9ea4f4da5362af066b_1440w.jpg
- · 5b6eb55d9630466faad7d5bc335535de.png
- · 08769904871c4a21a6ec0fc06783ff03.png
- · v2-b801cf39567dea90bec03ddd17ac8ad4_1440w.jpg
- · 198d60db27835ca3fc0eea0e.jpeg!800.jpg
- · c8a4cd5e1faf4f9ebff977a0fe061252.png
- · 68998b73a3b95.png
附件中心&附件聚合2.0
For Discuz! X2.5 © hgcad.com
For Discuz! X2.5 © hgcad.com
 v2-8646f77c807187710b056e1c2f85daea_1440w.jpg
v2-8646f77c807187710b056e1c2f85daea_1440w.jpg
助听器介绍:

本文主要介绍助听器的工作原理、构造及核心部件,帮助读者对助听器有一个整体性的认识。本文以耳背机为例进行介绍,其他机型不再一一赘述。工作原理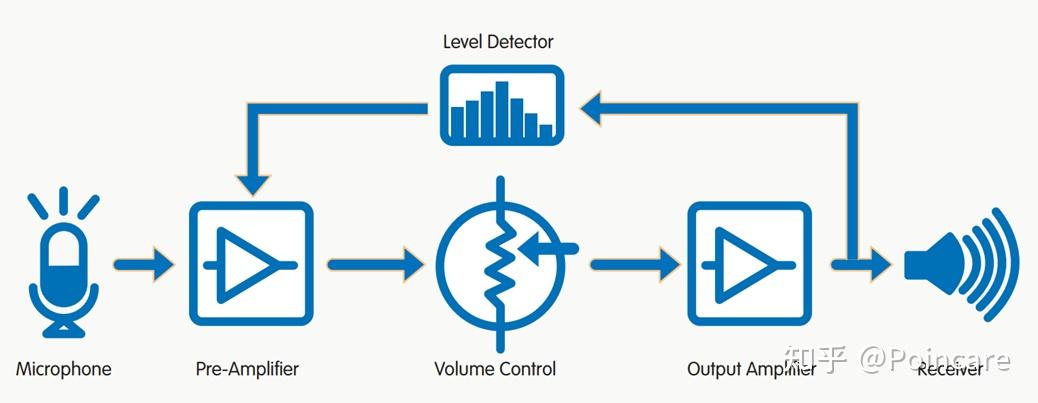
助听器工作原理简图整机构造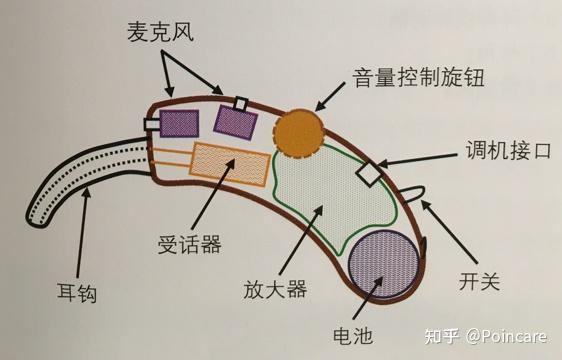
BTE 构造示意图核心部件介绍
助听器其实就是一个小型现场声音放大器。
工作原理非常简单,由麦克风采集声音,通过数字处理芯片对采集到的声音信号进行放大、降噪等一系列处理,最后经受话器将处理后的电信号转换为声信号播放。如下图所示:
助听器工作原理简图整机构造
助听器整机由以下几部分组成,下图为较老的耳背机构造示意图
- 音频链元器件:麦克风、受话器、音频处理芯片(即下图的放大器);
- 供电系统:电池;
- 机电系统:即机械结构(包括按键、音量旋钮等)、电路板等;
- 声学附件:主要包括耳塞、耳钩等;
- 其他部件:在一些旗舰机型上,还会有蓝牙芯片
- 、陀螺仪等实现特定功能的部件;
BTE 构造示意图核心部件介绍
这里重点介绍音频链、电池和蓝牙芯片;
麦克风麦克风,用于采集环境声音,将声信号转换成电信号,传递给数字处理芯片。
不同机型的麦克风数量有所不同。对于体积较大的机型,如BTE、ITC等,通常有两个麦克风;对于体积较小的机型,如CIC、IIC,则只有一个麦克风。
麦克风数量会与部分音频处理算法有关,如风噪抑制、方向性麦克风等,感兴趣想进一步了解的读者可参考助听器音频处理算法(二)-降噪
数字处理芯片数字处理芯片,对麦克风采集到的音频信号进行处理,包括A/D转换、音频处理算法、 D/A转换等。助听器常用的数字处理芯片有两种:
- 专用芯片:专门为助听器设计的芯片,其优点是性能功耗比高,可以满足用户对超长续航的要求,同时可以运行更复杂的算法。五大集团产品基本都是使用助听器专用芯片。
- 通用芯片:即蓝牙芯片,和TWS耳机一样。好处是集成度高、成本更低、天然支持无线功能,缺点是性能功耗比差,续航时间短。国内一些新势力玩家的产品多采用蓝牙芯片,特别是电商平台销售的TWS形态助听器。
俗称喇叭,将经处理之后的音频电信号转换为声信号再播放出来。
受话器根据最大声输出的差异可以分为不同的功率型号,常见的功率型号有 S(小功率)、M(中功率)、P(大功率)、UP(超大功率)。
功率越大,可输出的声音上限越大,也就可以满足听损程度更重的用户的需求。当然也有代价,助听器功率越大,其体积也会越大,适用的机型也就越少(部分机型对尺寸有着极限的要求,如深耳道定制机)
电池电池,为助听器系统供电,保证系统正常运行。
助听器常用的电池有两类,可充电锂电池和锌空电池。根据电池类型的差异将助听器分为充电款和电池款,两种机型也各有优缺点
电池款
- 优点:续航时间更久,不需要考虑锂电池使用久了之后性能衰减的问题,在电量不足时可以通过更换电池快速恢复满电;
- 缺点:更换电池比较麻烦,对手指灵巧性有较高的要求,对部分老年人来说有挑战;因为需要定期买电池,其使用成本也会更高;
充电款:与电池款相对;
蓝牙芯片对于采用专业芯片的无线款助听器,还会在机身内叠加一颗蓝牙芯片,实现蓝牙无线通讯。助听器的无线功能分为数据通信和音频流推送。
数据通信:接收手机发送的数据包,基于此实现自验配和APP指令控制两个典型功能;
音频流推送:接收手机推送的音频,如歌曲、微信语音、电话等。对于助听器来说,有三种典型的蓝牙音频协议
- MFA:即经典蓝牙音频协议,可以与所有的音频推送源配对接收音频推送,如笔记本、手机、车机智能电视等;一线品牌中只有锋力选择经典蓝牙支持MFA协议;
- MFi:助听器行业基于低功耗蓝牙为iOS系统搞的特殊协议;一线品牌除锋力外的另外五家均支持此协议;
- ASHA:助听器行业基于低功耗蓝牙为Android系统搞的特殊协议,通常只支持Android 10.0及迭代版本的手机终端;一线品牌除锋力外的另外五家均支持此协议;
对于主流的旗舰机型,除上述部件外还会有一些其他元器件以实现特定功能,如:
- 陀螺仪/运动传感器:检测用户运动状态;
- 传感器:如近红外传感器检测佩戴状态、心率传感器检测心率等;
- 近磁场感应:用于双耳数据互传,基于此实现更复杂的高级算法;
电声参数是衡量助听器硬件素质的关键指标,只有硬件底子打的好才能更好的发挥软件和算法的潜力。
本文主要参考《GB/T 14199—2010电声学助听器通用规范》对助听器的关键电声指标进行介绍,并简单介绍如何根据电声参数判断候选机型的硬件素质优劣。
电声参数介绍助听器电声参数主要包括:最大声输出(OSPL90)、满档声增益(FOG50)、等效输入噪声级(EIN)、总谐波失真(THD)、频率响应范围(FR)、额定电源电流消耗(Battery Drain)。以下逐个进行介绍
最大声输出(OSPL90)最大声输出,描述助听器的最大输出能力。这个指标非常重要,反应了助听器的输出功率是否够大,以及该输出没有超过患者的响度不适阈。
最大声输出值越大,助听器可输出的声音强度的上限值越高。又可细分为OSPL90(max)及 OSPL90(HFA),更精准的描述不同频段上助听器的最大输出能力。
评估标准参考:此参数与助听器受话器功率有关,对于专业级助听器,主流的M& 功率受话器,其OSPL90 在120dB以上,对于主打大功率的BTE,在130dB以上。
功率受话器,其OSPL90 在120dB以上,对于主打大功率的BTE,在130dB以上。
功率受话器,其OSPL90 在120dB以上,对于主打大功率的BTE,在130dB以上。防踩坑 tip:此参数是电商渠道重点宣传的参数之一,电商平台上许多TWS形态的助听器,其OSPL90一般不超过117dB,基本无法满足中度及以上听损用户的需求。读者朋友们请注意辨别!
频率响应范围(FR)
频率响应范围是指在按照测试要求测出的频响曲线(在恒定的自由场输入声压级时,助听器在耦合腔中产生的声压级随频率变化的函数曲线)的一个区间值。频率响应范围越大,可准确补偿的声音范围越宽广(例如音乐家就需要听到频率很高的声音)。频响范围与受话器功率有关,功率越大,频响越小(高频上限越小) 。对于普通功率,一般要求低频值小于200Hz、高频值大于6kHz。
评估标准参考:当前一线品牌旗舰款产品可以做到200~12kHz,主流产品产品可以做到200~8kHz,即使是一般的产品,也应当不少于200~6kHz。
测试要求:等效输入噪声级(EIN)
- 频率响应曲线:输入60dB SPL纯音,在参考测试自由控制位置所测得的频率相应曲线
- 频率响应范围:在基本频率相应曲线上,以1kHz、1.6kHz、2.5Hz三个频率描述对应的增益平均值(HFA增益)作一水平线,下移20dB再作一条平行线,该平行线与基本频率相应曲线的两个交点,即为助听器频率范围的低频限与高频限
等效输入噪声,反映助听器的内部噪声水平。 一般等效输出噪声要求控制在35dB SPL以下。
评估标准参考:当前一线品牌旗舰款产品EIN通常小于20dB,政采通常要求小于25dB。此值对用户意义不大,直接试听评估底噪是否明显、影响舒适性即可。
总谐波失真(THD)总谐波失真,衡量助听器的重要指标。总谐波失真值越小,表示信号的失真程度越低,音质越好。小于3%是助听器的一般目标。
评估标准参考:当前一线品牌旗舰款产品总谐波失真通常小于2%,政采通常要求小于2%;
额定电源电流消耗(Battery Drain)反映助听器在较低言语环境下的耗电程度。 电池电流的大小与助听器功率、放大器线路、授话器型号等均有关。额定电源电流消耗值越小,即机器越省电,续航时间越久。
评估标准参考:用户不需要关注此参数,只需要了解产品的续航时长即可。注意,不同使用场景下续航时长可能会相差极大,评估时务必留意续航值对应的使用场景,避免被误导。
如何从电声参数维度判断机器优劣?
如前文介绍,非常简单。EIN、THD越小越好,FOG50、FR越大越好,OSPL90合适就好。对于主推电商渠道的产品,判断方式则更简单,敢写出来的都是及格线以上的,不敢写出来的,大概率是不咋滴。对于写出来的,还需要留意产品介绍页里的春秋笔法:图文大字为虚,注释小字为实。
宽动态范围压缩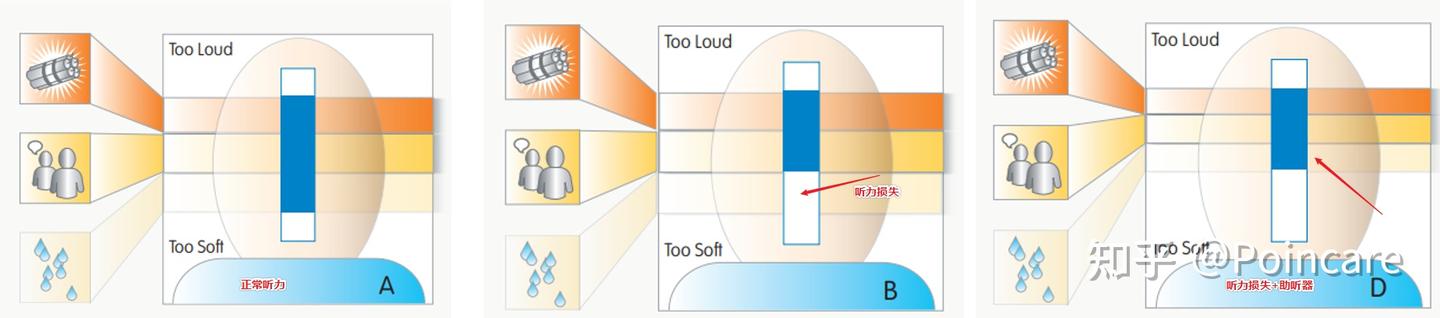
WDRC 效果示意简图原理简介
Phonak 验配软件精细调节界面截图
(Wide Dynamic Range Compression,简称WDRC)算法是数字助听器最核心的算法之一,其主要作用是对不同频率、不同强度的声音进行不同程度的补偿处理,从而将环境音转换到受损之后的听阈范围内,如下图所示:
WDRC 效果示意简图原理简介
WDRC 基于频域实现,其流程为:对输入系统的音频时域信号进行分帧、WOLA分解(加窗、FFT)、划分通道、根据WDRC的输入输出曲线计算增益,在频带上应用增益、WOLA综合,输出至DAC播放。
注意,这里提到了“通道”的概念。WDRC 算法涉及到两个“通道”的概念
信号处理通道数:音频信号FFT处理之后划分的通道,对每一个通道内的信号都需要计算处理;
可调通道数(Channel):验配软件界面上支持调节的通道数;对于助听器行业,“可调通道数”是少有的用户教育较好的指标,基本形成了“通道越多,助听器越好”的共识。注意,“通道越多”里的“通道”,指的是“可调通道数”的通道,而“信号处理通道数”更多是一个技术上的概念,并不对用户或验配师开放,因此无需关注。
然而近年来,不少行业玩家似乎在有意无意混淆“信号处理通道”和“可调通道数”的概念,特别是对于电商渠道销售的很多新产品,
WDRC 验配调参经常在各种平台上看到有小伙伴想了解如何验配助听器,这里对WDRC部分的验配调参的设置项进行简单介绍。
所谓WDRC 调试,其实就是调整增益表
(见下图)的值,这里结合下图进行介绍:
Phonak 验配软件精细调节界面截图
第一行,MPO:各个频率声音的最大声输出限制值,设定后助听器在这个频段最大也只能输出设定的声音强度,通常有UCL
(不适阈)测试结果确定,避免助听器输出声音过大导致用户聆听不舒适、甚至对听力造成二次损伤;
第二行,声音频率:图中的值为各个可调通道内声音频率的代表值(简单理解为通道内频率范围的中间值);
第三/四/五行,G50/G65/G80:助听器麦克风拾取到的声音的强度值,分别对应小声、中声和大声;
常说的调试,就是根据用户的反馈来调整白色表格部分,特别是下面三行格子里的值,举几个例子:
- 用户反馈小声说话听不到,那大致就应该G50(小声)一行调大一点,给更多的补偿;
- 用户反馈堵耳严重,很闷,那大致就应该调小G50/G65/G80这三行前几列的值,也就是降低低频部分的增益;
很多朋友经常会问,如何判断一个验配师是否专业?非常简单粗暴的一个方法,就是看其调试过程中是否会调试这张表,调的效果好不好。
专业的验配师,能够在和用户的互动过程中通过对话、观察分析出用户的问题,并将问题映射到增益表中并给出准确的解决方案。这既需要知识,更需要经验,非朝夕之功,是最能体现助听器行业“专业、服务”的点。
为了避免噪声一起放大导致用户佩戴不舒适,还必须要进行降噪处理才行。
本文介绍助听器的另一个核心算法——降噪。与WDRC相比,降噪更像是一个概念集合,因为涉及到的噪声类型多种多样,为了达到最好的效果,通常需要使用不同的手段对不同的噪声类型进行处理。
在正式介绍降噪之前,先补充一个概念——信噪比(Signal-Noise Ratio,简称SNR),即信号和噪声的比值。理想的降噪处理就是保留全部信号而去除全部噪声。而对于助听器来说,首先需要界定什么是信号、什么是噪声。通常会做如下假设:
- 信号:Mic 采集到的环境声里的言语信号;
- 噪声:Mic 采集到的环境声里的非言语信号、等效输入噪声,受话器播放后又被麦克风重新拾取的声音等;
当然,这个假设并不完全合理。非言语声对用户来说也可能是信号,比如走在马路上时后面来车的鸣笛声,言语声也可能是噪声,如鸡尾酒会时除了交流对象外其他人的说话声降噪原理
对于助听器来说,通常会针对以下几类典型噪声进行处理
稳态降噪对较平稳的噪声信号进行降噪处理。稳态降噪基于统计模型,并且假设“噪声是平稳信号,而语音是非平稳信号”。稳态降噪主要分为三步:
- SNR 估计,输入为带噪语音信号Y,Y = X(语音)+D(噪声);
- VAD(语音活动检测),根据语音检测结果,在无语音时,更新噪声估计值(即D的值);
- 噪声去除:计算各通道的增益,进行降噪处理(即计算 X = Y-D)
当前助听器的AI-降噪多采用RNNoise,通过大量样本数据训练出推理网络后部署在边缘侧。
风噪抑制
风噪是户外活动时经常遇到的场景,风噪本质是空气湍流撞击麦克风振膜的时候产生的一种噪声,有两个典型特点
- 能量强、且低频为主:由于是机械振动,因此能量集中在300Hz以下的低频段;
- 双麦信号相关性小:这个很好理解,风会对两个位置不同的麦克风造成不同的撞击,就好像风无法把两片树叶吹出一致的摆幅;
基于上述两个特点,也就有了简单版和进阶版两种风噪抑制处理策略。
简单版:当检测到低频信号异常高时,直接拉低低频的增益值,即降低低频的声音;
进阶版:检测两个麦克风信号的一致性,信号一致性越差,有风噪的可能性越大,然后计算出增益值进行降噪处理。
无论是哪个策略,也都是分为两步,先做风噪声检测,再做风噪声去除。差别在于进阶版对于风噪信号的检测和抑制程度都会更准确。
瞬噪抑制
瞬噪也是助听器用户经常遇到的场景,比如鸣笛声、拍手声等。瞬噪的特征是时域上像一个冲击波,即突来有一个很大的声音。瞬噪抑制也是分为瞬噪检测和瞬噪去除两步。检测方法也比较多,比如基于方差统计量的瞬噪检测、基于高低频能量比值的瞬噪检测方法等。
方向性麦克风
除了上述的三种之外,还有一种常见的策略——方向性麦克风。大概原理为通过不同的方向性模式来拾取指定方向的信号、屏蔽其他方向的信号,从而有效的提高SNR。方向性麦克风常见的典型模式有:
Signia 验配软件方向性模式设置图
降噪设置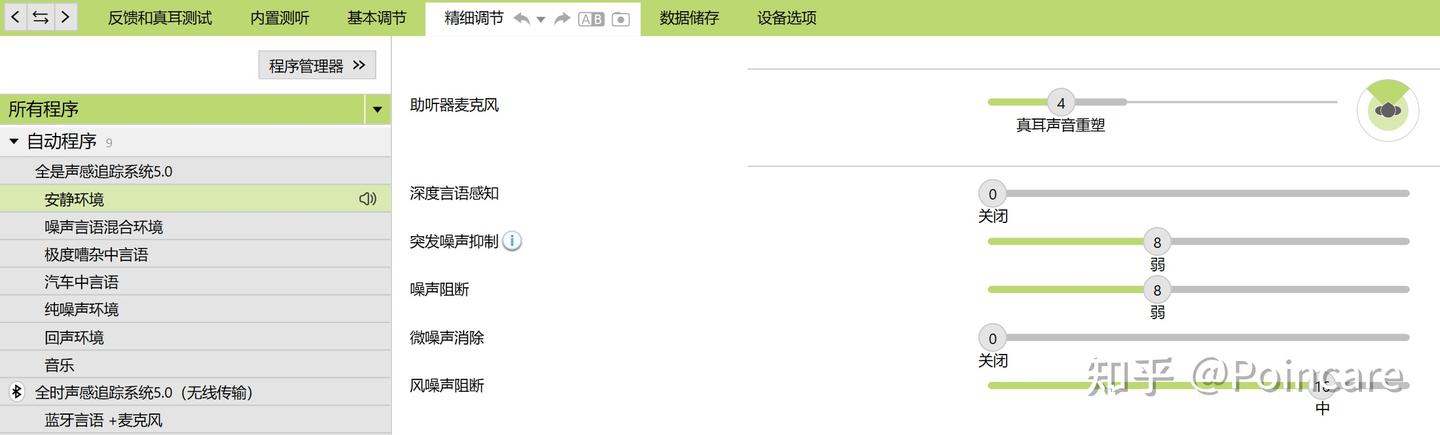
锋力验配软件 降噪设置界面
- 全向性:即无差别拾取周围360°的声音;
- 定向性:拾取前方的声音,抑制其他方向的声音;对于做的比较好的玩家,还可以设置定向的角度值,角度越小,定向范围内的聆听效果越好;
- 自适应方向性:助听器实时判断周围的信号或噪声来源,确定之后抑制噪声源方向的信号;
Signia 验配软件方向性模式设置图
除了上述典型模式外,还有其他更高阶的方向性算法,比如Signia IX平台主推的波束方向性。感兴趣的读者可以在Signia官网进一步了解详细信息。
降噪设置
很多小伙伴们也会问到如何设置降噪处理参数,一般情况下采用厂家提供的默认参数即可,有特殊的个性化需求时,根据场景对各个降噪模块进行调整即可,调整界面如下图所示
锋力验配软件 降噪设置界面
这里需要注意一点,降噪等级越高,其抑制策略越激进,会不可避免的伤及语音信号。所以不要贪图最高的等级,最合适的就是最好的,所谓“中庸”之道是也。
助听器的主流机型上还有一些常见算法,本篇进行补充介绍。
啸叫截除啸叫是指在使用助听器时,由于麦克风与受话器之间形成回路,信号循环放大而产生的一种可听见的声音振荡。啸叫是助听器用户最常见的问题之一,不仅严重影响用户体验,还限制了助听器能提供的最大稳定增益(也就是能放大的程度);
啸叫截除算法
并不是为了解决听损的问题,而是为了解决用户因为佩戴助听器引入的新问题。这个模块介绍起来比较麻烦,而笔者最怕麻烦,所以这里就不展开了,感兴趣的读者可以参考相关书籍或论文。
场景分类由于用户佩戴助听器时的声场景非常复杂,因此主流助听器通常都会配置一个场景分类算法
。当用户佩戴时,助听器可以实时自动识别出当前声场景的类型,然后切换到更适合当前场景的参数,实现更好、更精准的处理效果。
场景可以简单分成四类,具体如下:
- 安静无言语:既不需要降噪,也不需要放大语音;
- 安静言语:主要是语音放大,因此可以采用较保守的降噪处理,避免伤及语音;
- 噪声无言语:主要是降噪,并且因为没有语音,可以做更激进的降噪处理;
- 噪声言语:既需要降噪,也需要对语音放大,需要在降噪和放大之间做平衡;
当然,一线品牌的旗舰机会对场景做更精细的划分,如Widex 旗舰产品最高技术等级支持11个场景分类。对某些宣称几百几千种场景分类的……,不知道说啥好了。感兴趣的读者可以自行研究,此处不再赘述。
高频重塑对于部分高频损失特别严重的用户,通过放大补偿仍无法让其听到高频声音,此时不得不采用一些特殊的技术手段,将高频声音搬到低频频段,才能让用户重新听到高频声(当然听到的其实是频率降低之后的声音)。
高频重塑有两种常见策略:
- 频率压缩,即将所有频段的声音压扁。例如,原声音频率范围为200Hz~8000Hz,压缩后变为200Hz~4000Hz;
- 频率转移,即将高频的声音搬到低频。例如,原声音频率范围为200Hz~8000Hz,频率转移后,其200~5000Hz的声音不变,将5000Hz~8000Hz的声音搬到了3000~5000Hz;
耳鸣有多恼人就不必多说了。大多数助听器还会配置耳鸣掩蔽模块,播放特定音频以掩蔽耳鸣,常见的耳鸣掩蔽音类型有:
- 白噪声、粉噪声等;
- 特定音频:如海浪声、篝火声;
当然还有厂家用算法做更精细的掩蔽策略。读者知道有这个常见算法就足够了,这里不再赘述。
同一主题附件字上面广告
Archiver|手机版|小黑屋| 探索掌握未知、共创美好未来
GMT+8, 2026-3-23 09:48 Powered by Discuz! X3.5